Route Optimization at AhaMove
This is a repost from my medium post
Introduction
Vehicle Routing Problem (VRP) is a huge topic relating to route optimization for a fleet of vehicles. There are quite a lot of derivatives from this general problem such as Capacitated VRP, Multiple Pickup-Delivery VRP, etc… In fact, at AhaMove, we have deployed VRP in various use-cases:
- Driver Routing: A driver can have multiple pickup-delivery stops through their route, hence we apply Multiple Pickup-Delivery Travelling Salesman Problem (PD TSP) algorithm to find an optimal route for each driver.
- Same Day Service: From a mass single pickup-delivery orders across the city, we form optimal routes satisfying several constraints like max parcels, max distance, etc… by an algorithm called Multiple Pickup Delivery Vehicle Routing Problem (PD VRP)
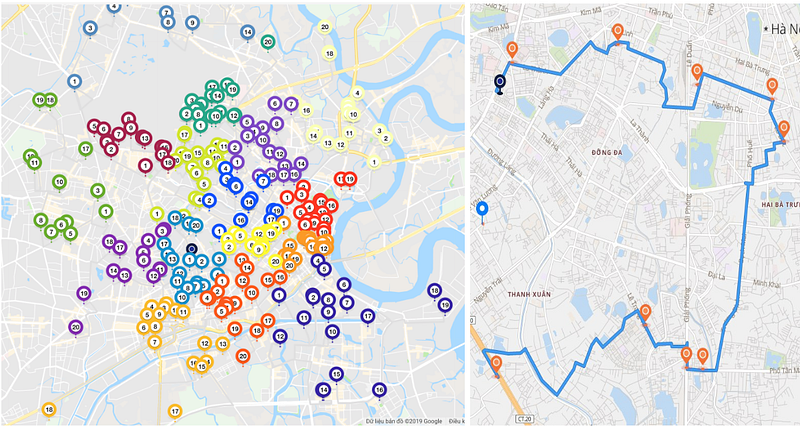
- Hub Delivery: HUB is a classical last-mile delivery model where from a single location, a big volume of parcels are sent to their destinations. In technical terms, HUB delivery represents the one-to-many (1-N) vehicle routing problem (CVRP). While this problem may be less complicated and less constraints than its variants, it requires capability to optimize a huge volume of parcels (up to thousands) at the same time, that makes it somehow outstanding and challenging to solve.
- Multiple Hubs/Stores Delivery: this demand happens on merchants having multiple stores/locations and they want the system to choose the nearest one to deliver their parcels. Hence, we develop a new selective-depot VRP algorithm (SDVRP) to fulfill this request. Indeed, SDVRP is an upgraded version of CVRP.
Technical Challenges
In order to find optimal routes of a mass volume of parcels to fit available fleet of vehicles, there are some technical challenges need to be addressed:
VRP solver: we need to develop VRP algorithms to satisfy multiple constraints in route optimization problems such as max distance, max parcels, time windows constraints, multiple depots, etc…. In details, the solver will get input of all problem criteria and stop points’ distance matrix, then process and result in clusters of trip. The more stop points and criteria, the more time it takes to process along with more CPU and Memory requires. So, the challenge here is we need a vrp solver flexible enough for multiple kinds of constraints and auto-scalable to meet fluctuating demands. We manage to build such engine, but accept its trade-off as well: the algorithm’s just fast enough because it serves multiple purposes rather than be optimized for a specific problem. And we autoscale the engine by moving it into aws lambda (which supports up to 3GB RAM and 15 running minutes).
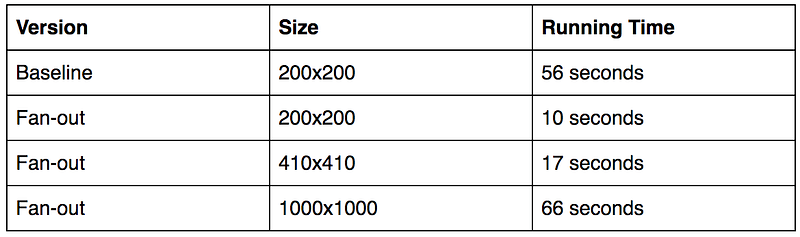
Distance Matrix: we need a routing engine that can provide us a distance matrix as fast and accurate as possible. It means that, our routing engine has to calculate the travelling distance for many vehicle types such as bike, cars, so on… based on the real road networks instead of crowfly distance. The engine is also able to calculate a mass number of locations. For example, if we have 200 locations, we need to build a distance matrix of 200x200 = 40k distance values, within a very short time (seconds). To solve this challenge, we build 2 components, a routing engine for real-world travelling calculation and a distance matrix builder to aggregate results from our routing engine. The baseline benchmark is 56 seconds for a 200x200 distance matrix in a HIGH CPU 4-Cores Digital Ocean Droplet. Here, if we have more vm instances at calculation, we can make it even faster, but the cost will be higher if we keep all instances alive all day. Fortunately, the new product of GCP called Google Cloud Run fit our use-case perfectly, so we make use of Google Cloud Function and Google Cloud Run to build a new distance matrix builder with fan-out pattern to speed up calculation up to 3x. Moreover, we also found an interesting technique called Nearest Selection that can both reduces the distance matrix calculation efforts much smaller and filters out “bad” edges by giving them a very high constant value so that our vrp solver can ignore such edges. Now, we can reduce the calculation size of distance matrix at 17% of the original one. Or in other words, we speed up our vrp system up to 6x with zero cost of maintenance (as them all are serverless).
Clustering: due to the nature of mass volume constraint, the HUB Delivery is a special form of VRP that need to be pre-processed to make it feasible for traditional VRP solver at smaller scale. This pre-vrp phase is called clustering, to divide the original order batch into smaller clusters having size under predefined value (known as the max capacity of VRP solver, say 200 for example). Clustering methodology is quite opinionated due to real-world use-cases:
- Unbiased clustering (global optimization) if the volume is not dense enough and evenly distributed across city, this methodology is applied by some unsupervised ML techniques like Kmeans Samesized, DbScan, etc… to produce clusters. This way is good for VRP solver but may be unfriendly to drivers since routes can spread throughout various districts.
- Biased clustering (local optimization): if destinations have tendency of recurring and the volume is dense/big enough, dividing parcels based on its administrative delivery area such as ward, district would be nicer for shipper and easier to control for users, but the optimization score would be higher somehow.
Long running time: Our vrp solver can process up to 15 minutes per problem on aws lambda, but aws gateway is very limited to 30 seconds, other http proxy approaches can extend longer but still timeout after 2–3 minutes and quite tricky for both development and maintenance. In the real world, vrp at large scale (thousands of orders) has a nature challenge “long running time”, because the engine needs more time to process such a high volume of locations. After all, we changed the way to interact with our vrp system, instead of normal request-response, we use mechanism “trigger-polling” where we provide an http endpoint to trigger VRP solver which will return a polling url very quickly, then consumers can use this pooling url to check if their result is ready or not. *This mechanism is the public way for external system to communicate with our vrp engine; for internal system, we use event handler via webhook to receive the engine output.
Conclusion
VRP is interesting because it has many use-cases and multiple technical aspects. My lesson learnt is: don’t pay too much attention on the algorithm itself because you may just be able to make very little improvement on it, say 1%-2% better . Instead, look at other principles: divide and conquer, parallelism as well as making use of latest technologies like serverless, those can help you not only improve the performance of system but also reduce the burden on maintaining it at scale.
One more thing, we are opening our VRP apis for free, please take a look at our documentation.